Inter-Coder Reliability
Before the coding of the entire sample using the online interface, the human coders performed a pretest to ensure their correct understanding of the selection protocol. The pretest consisted of a coding exercise of 150 items for which the coders had to code the items as thematically relevant or irrelevant.
In these exercises, the coders had to code some example material in the languages they are supposed to work on, in the same way, they would code them later in the interface. In a next step we used the individual coding decisions of all of the coders to calculate the majority decision for each item, i.e. if the coded item was thematically relevant or irrelevant. The majority decision was then compared to the individual coding decision of each coder. The agreement scores we calculated on these are shown below.
Results
The following figure shows the results of the reliability testing.
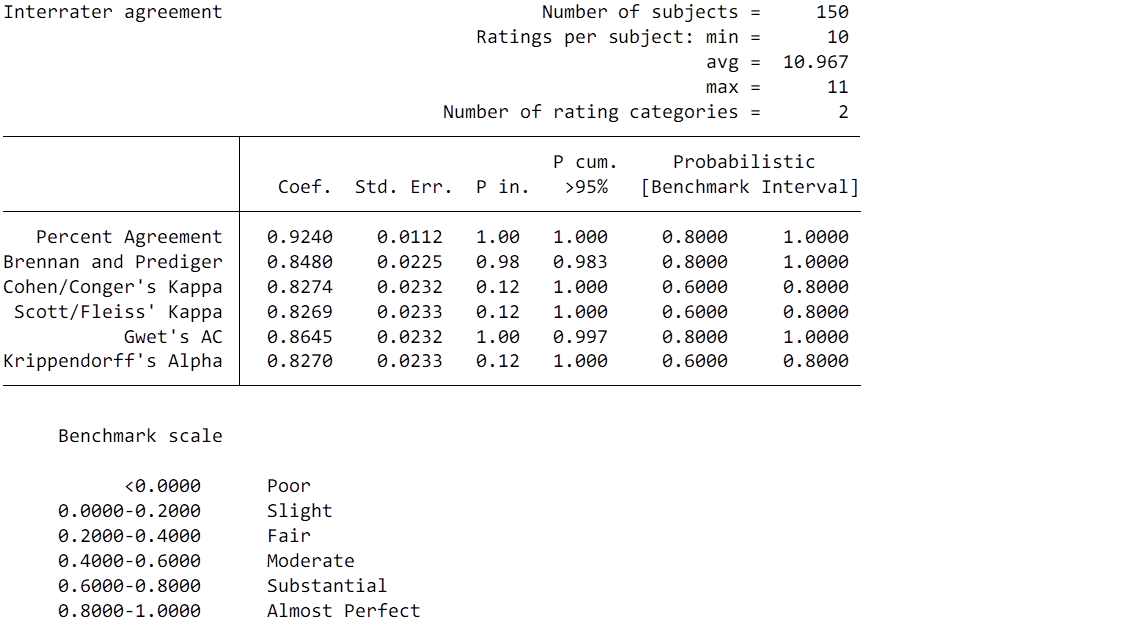
The interrater agreement was calculated based on the framework presented by Klein (2018). The material that is needed for the reproduction is attached below.
Materials
References
Klein, D. (2018). Implementing a general framework for assessing interrater agreement in Stata. Stata Journal, 18(4), 871-901. https://doi.org/10.1177/1536867X1801800408